安装与配置
推荐先使用 GitHub Releases 中的完整包。源码运行适合开发者,普通用户不要只下载 GitHub 页面上的源码压缩包。
1. 下载发布包
Section titled “1. 下载发布包”打开 Releases 页面,下载对应平台的构建包。
| 文件名 | 是什么 | 适合谁 |
|---|---|---|
sakura-v0.9.x-windows-x64.zip | Windows 完整包,包含项目文件和 runtime | Windows 新手首选 |
runtime-windows-x64.zip | 只有 Windows 预置 Python 运行环境 | 拉源码但缺少 runtime 的用户 |
sakura.char | 默认 Sakura 角色包,含语音权重 | 想使用默认角色的用户 |
models--sentence-transformers--all-MiniLM-L6-v2.zip | 长期记忆所需的本地向量模型 | 首次启动自动下载失败时手动导入 |
如果只是想运行桌宠,下载完整包。runtime 包不是完整程序,单独下载后不能直接启动。
2. 安装依赖
Section titled “2. 安装依赖”解压完整包后,进入解压出来的软件目录。
| 平台 | 安装方式 |
|---|---|
| Windows | 双击 install.bat,等待依赖安装完成 |
| macOS | 双击 install.command,或在终端运行 bash scripts/install.sh |
| Linux | 从源码运行时,执行 bash scripts/install.sh |
如果是直接拉取源码,需要先从 Release 页面下载对应平台的预编译依赖包,把里面的 runtime 文件夹放到项目根目录,再运行安装脚本。
3. 启动 Sakura
Section titled “3. 启动 Sakura”| 平台 | 启动方式 |
|---|---|
| Windows | 双击 start.bat |
| macOS | 双击 start.command,或运行 bash scripts/start.sh |
| Linux | 运行 bash scripts/start.sh |
首次启动会进入引导配置流程。
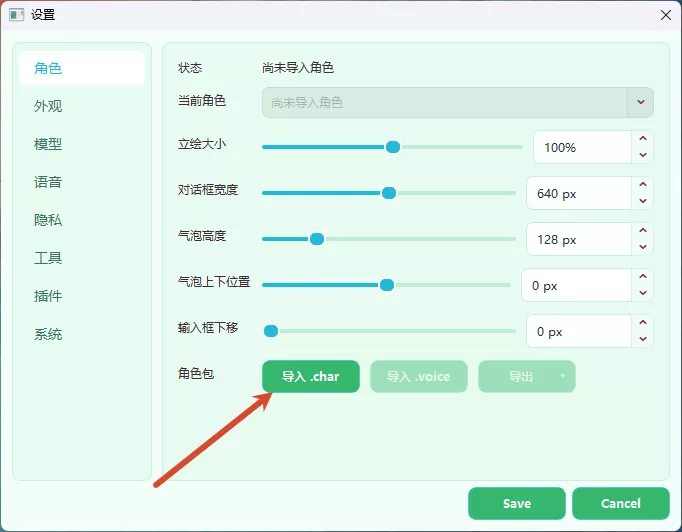
4. 导入角色包
Section titled “4. 导入角色包”从 Releases 页面下载 .char 角色包。Release 附件中,大小约 300MB、以 .char 结尾的文件通常是包含语音的完整角色包。
下载后在软件设置中点击”导入 .char”,选择文件完成导入。
5. 配置模型
Section titled “5. 配置模型”进入”模型”页面,填写 Base URL、API Key 和模型名称。
Sakura 需要模型支持图像输入。屏幕观察、主动观察等功能会把截图发给模型;如果模型不支持多模态,相关功能会失败。新手优先选 Gemini Flash 系列,不建议用 DeepSeek 系列作为 Sakura 主模型。
填写完成后,点击”检测模型”获取可用模型列表,再点击”测试 API”验证连通性。
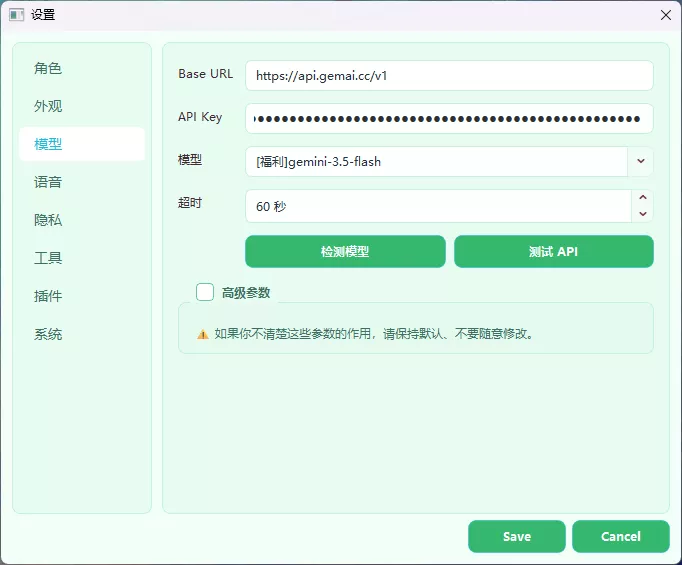
更详细的字段说明见API 配置。
6. 配置语音
Section titled “6. 配置语音”TTS 是可选功能,不配置也可以正常使用,只是没有语音。
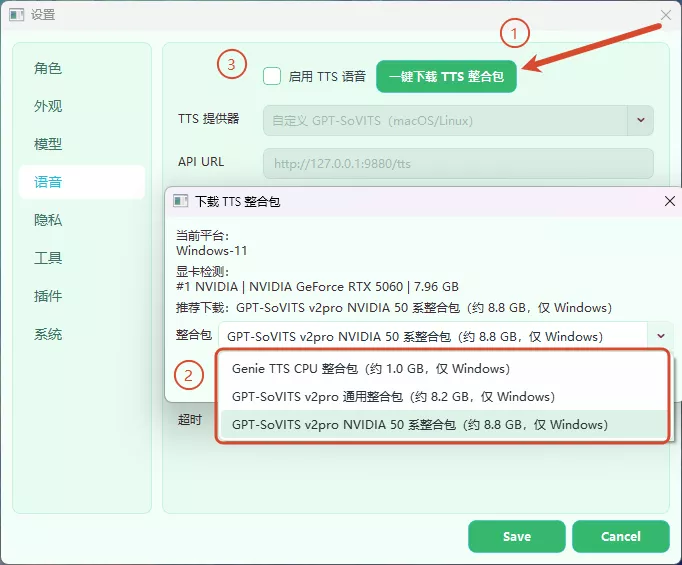
软件内提供了一键下载整合包:
| 方案 | 适合谁 |
|---|---|
| 50 系整合包 | RTX 50 系列显卡用户 |
| 通用整合包 | 其他 NVIDIA 显卡用户 |
| CPU 整合包 | 无独显或不支持 CUDA 的用户 |
下载完成后在软件内直接启动 TTS 服务即可。
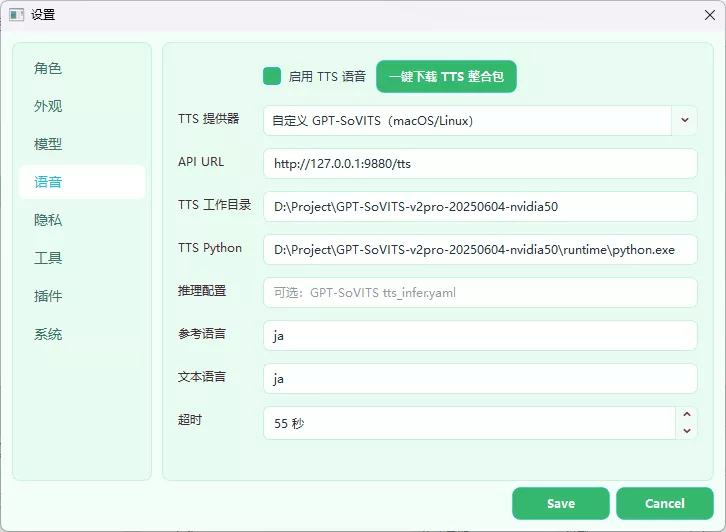
AMD 显卡用户如需 GPU 推理,可自行安装 GPT-SoVITS,然后在软件中选择”外置 GPT-SoVITS”模式,填写服务地址。
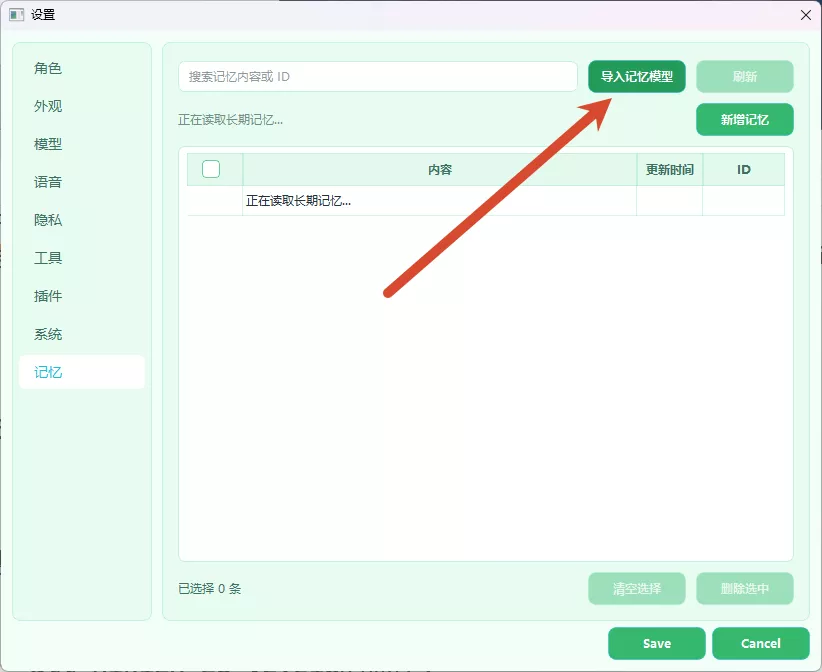
7. 长期记忆模型
Section titled “7. 长期记忆模型”首次启动时,软件在后台自动下载长期记忆所需的本地向量模型。下载过程中可以正常使用。
遇到网络问题导致下载失败的话,从 Releases 页面手动下载 models--sentence-transformers--all-MiniLM-L6-v2.zip,然后在软件内导入。
8. 更新版本
Section titled “8. 更新版本”- 关闭正在运行的 Sakura。
- 从 Releases 页面下载同平台的最新完整包。
- 解压后把新包里的文件复制到原 Sakura 目录,遇到同名文件选择覆盖。
- 如果启动失败,重新运行一次安装脚本。
- 正常启动后,配置和角色数据会保留。